|
Программа моделирует совокупность компонентов исследования
как некоторую часть объекта, который называется «Динамическая норма гемодинамики».
Объект моделирования – есть программная модель как источник анализируемой
информации.
Цель применения программы: анализ текущей и прогнозируемой
нормы гемодинамики работников локомотивных бригад при медицинском обеспечении
безопасности на железнодорожном транспорте.
Задачи: программа предназначена для
интеграции в комплекс АСПО без привлечения дополнительных средств ее адаптации
и обучения персонала. Программа выполняет задачу адаптации к системе данных
АСПО и повышает качество измеряемого и анализируемого сигнала. Определяет
текущее и прогнозируемое во времени состояние компонентов исследования для
диагностического заключения о состоянии объекта с использованием графических
вариантов выхода модели.
Функционирование программного обеспечения происходит на персональных
компьютерах типа IBM PC не ниже класса Pentium при
поддержке операционных систем (ОС) Windows 98, 2000, NT, XP, Vista.
Учитывая целесообразность совмещения базы данных ведения картотеки пациентов и
проводимых исследований на основе расчетов пространственно-временной модели, в
программном обеспечении реализована концепция некоторой системы управления
этими данными и численными методами расчетов. Проектирование системы начинается
с обработки отношений в базе данных типа «Картотека медицинских исследований».
Далее система адаптируется к СУБД, управления данными, использует определенную
в АСПО технологию хранения и считывания данных приборов измерения параметров
гемодинамики.
В качестве инструмента выполнения
проекта управляющей системы выбраны: интерактивное ANFIS,
объектно-ориентированный язык Object Pascal со
стандартной библиотекой визуальных компонент проектирования. Концепция
объектно-ориентированного программирования, реализованная в интерактивном ANFIS,
позволяет рассмотреть средства статистической обработки данных параметров
гемодинамики, как систему родословных отношений объектов, прогрессирующую по
мере совершенствования существующих и новых перспективных моделей сбора,
анализа исходной информации. Доступ к данным картотеки пациентов и измерениям
происходит по типу «Клиент-сервер», осуществляется через компонентный интерфейс
Delphi с системой доступа к базам данных
(БД) фирмы Borland (Borland Database Engine, или BDE).
Это первая функциональная часть управляющей системы. Вторая - реализация
численных методов, описанных входными языками математических пакетов (Mathcad, Matlab и т.п.). Управление расчетами происходит на основе OLE (Object linking and embedding) технологии.
В качестве такого ресурса
моделирования использовались входной язык, модули программирования и
графической визуализации математической системы Mathcad версии 11.0а.
Результат:
разработана программа управления системой ресурсов информационного обеспечения
расчета параметров гемодинамики и имеющая расширение пространственно-временного
анализа основных компонентов медицинской нормы, используются элементы
графического вывода для целей интерпретации исходных данных и диагностического
заключения.
Обмен административной оболочки пользователя с вычислительными ресурсами
математических пакетов происходит по системной технологии OLE – вычислительные
ресурсы методов идентификации и прогноза есть исходные данные COM сервера
Mathcad для административной оболочки, выполненной по схеме многодокументного
интерфейса.
2.2.2
Управление иерархией нечеткого вывода интерактивным пакетом ANFIS
ANFIS - это
аббревиатура Adaptive-Network-Based Fuzzy Inference System - адаптивная сеть
нечеткого вывода. Она была предложена Янгом (Jang) в начале девяностых. ANFIS
является одним из первых вариантов гибридных нейро-нечетких сетей - нейронной
сети прямого распространения сигнала особого типа. Архитектура нейро-нечеткой
сети изоморфна нечеткой базе знаний. В нейро-нечетких сетях используются
дифференцируемые реализации треугольных норм (умножение и вероятностное ИЛИ), а
также гладкие функции принадлежности. Это позволяет применять для настройки
нейро-нечетких сетей быстрые алгоритмы обучения нейронных сетей, основанные на
методе обратного распространения ошибки. Ниже описываются архитектура и правила
функционирования каждого слоя ANFIS-сети.
ANFIS
реализует систему нечеткого вывода Сугено в виде пятислойной нейронной сети
прямого распространения сигнала. Назначение слоев следующее: первый слой -
термы входных переменных; второй слой - антецеденты (посылки) нечетких правил; третий
слой - нормализация степеней выполнения правил; четвертый слой - заключения
правил; пятый слой - агрегирование результата, полученного по различным
правилам.
Входы сети в
отдельный слой не выделяются. На рис. 2.2. изображена ANFIS-сеть с двумя
входными переменными (x1 и x2) и четырьмя нечеткими
правилами. Для лингвистической оценки входной переменной x1
используется 3 терма, для переменной x2 - 2 терма.
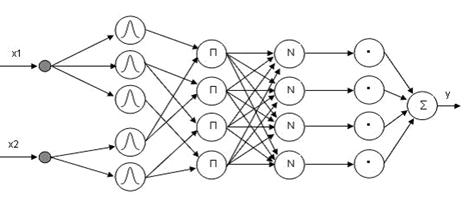
Рисунок 2.2 – Пример ANFIS-сети
Введем
следующие обозначения, необходимые для дальнейшего изложения:
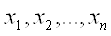 - входы сети; - входы сети;
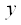 - выход сети; - выход сети;
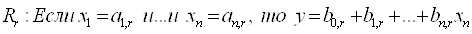 - нечеткое правило с порядковым
номером - нечеткое правило с порядковым
номером 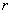 ; ;
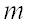 - количество правил , - количество правил , ; ;
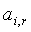 - нечеткий терм с функцией
принадлежности - нечеткий терм с функцией
принадлежности 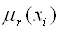 , применяемый для
лингвистической оценки переменной , применяемый для
лингвистической оценки переменной 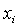 в r-ом
правиле ( в r-ом
правиле (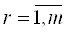 , ,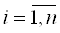 ); );
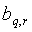 - действительные числа в
заключении r-го правила ( - действительные числа в
заключении r-го правила (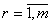 , ,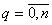 ). ).
ANFIS-сеть
функционирует следующим образом.
Слой 1. Каждый узел первого слоя
представляет один терм с колоколобразной функцией принадлежности. Входы сети 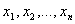 соединены только со своими
термами. Количество узлов первого слоя равно сумме мощностей терм-множеств
входных переменных. Выходом узла являются степень принадлежности значения
входной переменной соответствующему нечеткому терму: соединены только со своими
термами. Количество узлов первого слоя равно сумме мощностей терм-множеств
входных переменных. Выходом узла являются степень принадлежности значения
входной переменной соответствующему нечеткому терму:
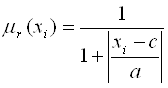 , (2.1) , (2.1)
где a, b и
c - настраиваемые параметры функции принадлежности.
Слой 2. Количество узлов второго слоя
равно m. Каждый узел этого слоя соответствует одному нечеткому правилу. Узел
второго слоя соединен с теми узлами первого слоя, которые формируют антецеденты
соответствующего правила. Следовательно, каждый узел второго слоя может
принимать от 1 до n входных сигналов. Выходом узла является степень выполнения
правила, которая рассчитывается как произведение входных сигналов. Обозначим
выходы узлов этого слоя через 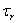 , ,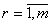 . .
Слой 3. Количество узлов третьего слоя
также равно m. Каждый узел этого слоя рассчитывает относительную степень
выполнения нечеткого правила:
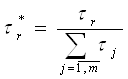 . (2.2) . (2.2)
Слой 4. Количество узлов четвертого
слоя также равно m. Каждый узел соединен с одним узлом третьего слоя а также со
всеми входами сети (на рис. 2.1. связи с входами не показаны). Узел
четвертого слоя рассчитывает вклад одного нечеткого правила в выход сети:
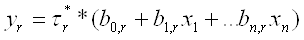 . (2.3) . (2.3)
Слой 5. Единственный узел этого слоя
суммирует вклады всех правил:
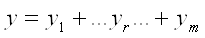 . (2.4) . (2.4)
Типовые
процедуры обучения нейронных сетей могут быть применены для настройки
ANFIS-сети так как, в ней использует только дифференцируемые функции. Обычно
применяется комбинация градиентного спуска в виде алгоритма обратного
распространения ошибки и метода наименьших квадратов. Алгоритм обратного
распространения ошибки настраивает параметры антецедентов правил, т.е. функций
принадлежности. Методом наименьших квадратов оцениваются коэффициенты
заключений правил, так как они линейно связаны с выходом сети. Каждая итерация
процедуры настройки выполняется в два этапа. На первом этапе на входы подается
обучающая выборка, и по невязке между желаемым и действительным поведением сети
итерационным методом наименьших квадратов находятся оптимальные параметры узлов
четвертого слоя. На втором этапе остаточная невязка передается с выхода сети на
входы, и методом обратного распространения ошибки модифицируются параметры
узлов первого слоя. При этом найденные на первом этапе коэффициенты заключений
правил не изменяются. Итерационная процедура настройки продолжается пока
невязка превышает заранее установленное значение. Для настройки функций
принадлежностей кроме метода обратного распространения ошибки могут использоваться
и другие алгоритмы оптимизации, например, метод Левенберга-Марквардта.
2.2.3 Алгоритм диагностики
Информация, полученная от врача и
больного, включает нечеткость, выраженную ЛЗИ. Для вычислений необходимо
преобразовать эти значения в числовые значения истинности (ЧЗИ). Для их
количественной оценки использованы функции принадлежности. В данной системе
такие понятия, как «немного», «очень» для симптомов и «часто», «вероятно» и др.
для взаимосвязи между болезнями и симптомами, представлены ЛЗИ (семь уровней).
При этом необходимо установить, каким образом выбирать по функции
принадлежности каждого ЛЗИ значения принадлежности. Такие значения назовем
а-сечением, а значение, выбранное для 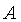 ,
обозначим ,
обозначим 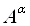 . Обычно . Обычно 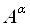 имеет одно значение, но в
целях сохранения нечеткости в словах более естественно использовать интервал
значений, например для ЛЗИ "UN" (неизвестное) введем интервал [О, 1].
Таким образом будем задавать интервал значений принадлежности для всех ЛЗИ,
т.е. имеет одно значение, но в
целях сохранения нечеткости в словах более естественно использовать интервал
значений, например для ЛЗИ "UN" (неизвестное) введем интервал [О, 1].
Таким образом будем задавать интервал значений принадлежности для всех ЛЗИ,
т.е.
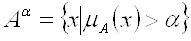 . (2.5) . (2.5)
Связь между ЛЗИ, а-сечением и
значениями принадлежности показана на рис. 2.3. В системе существует база
данных, в которой все функции принадлежности и а-сечение являются координатами,
константами и другими параметрами.
Алгоритм выводов следует из формул (2.6)
и (2.7).
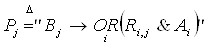 , (2.6) , (2.6)
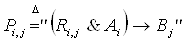 (2.7). (2.7).
При этом предполагается, что 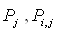 -нечеткие подмножества
множества V ЛЗИ, т. е. очень правдивые и выпуклые подмножества. Если применить
к формулам (2.6) и (2.7) нечеткие правила «модус поненс» и «модус толлекс», то
получатся следующие взаимосвязи между болезнями и симптомами: -нечеткие подмножества
множества V ЛЗИ, т. е. очень правдивые и выпуклые подмножества. Если применить
к формулам (2.6) и (2.7) нечеткие правила «модус поненс» и «модус толлекс», то
получатся следующие взаимосвязи между болезнями и симптомами:
для 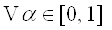
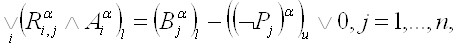 (2.8) (2.8)
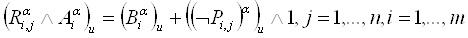 , (2.9) , (2.9)
где 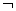 означает
отрицание в нечеткой логике, L
указывает нижнюю границу (см. дополнение об операциях в нечеткой логике).
Зададим наблюдаемые симптомы означает
отрицание в нечеткой логике, L
указывает нижнюю границу (см. дополнение об операциях в нечеткой логике).
Зададим наблюдаемые симптомы 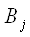 ,- и
знания ,- и
знания 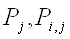 , ,
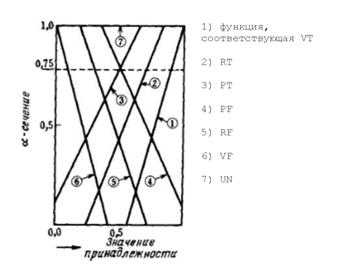
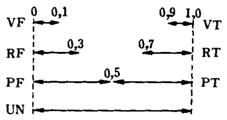
Рисунок 2.3 Связь между ЛЗИ, а и
значениями принадлежности
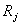 , и обнаружим все болезни { , и обнаружим все болезни {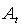 }. }. 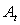 можно получить, найдя
общее решение формул (2.8) и (2.9). При этом достоверности знаний можно получить, найдя
общее решение формул (2.8) и (2.9). При этом достоверности знаний 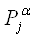 , ,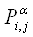 , ,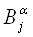 можно определить через
интервал их значений ([нижнее значение, верхнее значение]) следующим образом: можно определить через
интервал их значений ([нижнее значение, верхнее значение]) следующим образом:
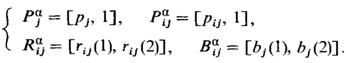 (2.10) (2.10)
Кроме того, определим расстояние
между симптомом и знаниями следующим образом:
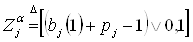 , (2.11) , (2.11)
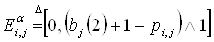 . (1.12) . (1.12)
Введем следующие множества интервалов
значений для знаний и расстояний: для любых i, j
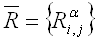 , , 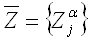 , ,
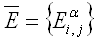 . (2.13) . (2.13)
Страницы: 1, 2, 3, 4, 5, 6
| 
